ヒトが読み書きのシステムを開発し始めたのは過去数千年以内のことだ。 我々の読書能力は他の動物種と一線を画すものだが、数千年はヒトの脳が特に読書に専念する新しい領域を進化させるにはあまりにも短い時間枠だ。 このスキルの発達を説明するために、一部の科学者は、元々他の目的のために進化した脳の部分が読書のために「リサイクル」されたと仮定した。2020年8月4日にNature Communicationsのオンラインで掲載されたMITの神経科学者らによるこの論文は、「下側頭皮質は未訓練のサルの正射図処理の皮質前駆体である可能性」と題されている。
ヒトが読み書きのシステムを開発し始めたのは過去数千年以内のことだ。 我々の読書能力は他の動物種と一線を画すものだが、数千年はヒトの脳が特に読書に専念する新しい領域を進化させるにはあまりにも短い時間枠だ。 このスキルの発達を説明するために、一部の科学者は、元々他の目的のために進化した脳の部分が読書のために「リサイクル」されたと仮定した。
一例として、彼らは、オブジェクト認識の実行に特化した視覚システムの一部が、正字法と呼ばれる読書の主要なコンポーネント、つまり書かれた文字や単語を認識する機能に転用されたことを示唆している。 MITの神経科学者らによる新研究は、この仮説の証拠を提供している。
この研究成果は、読む方法を知らない非ヒト霊長類であっても、下側頭葉皮質( inferotemporal cortex)と呼ばれる脳の一部が、意味のない単語と単語を区別したり、単語から特定の文字を取り出すなどのタスクを実行できることを示唆している 。
「この研究は、視覚処理の神経メカニズムの急速な発達への理解と霊長類の重要な行動(ヒトの読書)との間の潜在的なつながりを紐解いた」と Rishi Rajalingham博士(MIT 脳・認知科学部門の責任者、マクガバン脳研究所の研究者、および本研究の筆頭著者)は述べた。2020年8月4日にNature Communicationsのオンラインで掲載されたこのオープンアクセスの論文は、「下側頭皮質は未訓練のサルの正射図処理の皮質前駆体である可能性(The Inferior Temporal Cortex Is a Potential Cortical Precursor of Orthographic Processing in Untrained Monkeys.)」と題されている。
この論文の他のMITの著者には、ポスドクのKoitij Kar博士、およびテクニカルアソシエイトのSachi Sanghavi氏が含まれている。 この研究チームには、コレージュ・ド・フランスの実験的認知心理学教授であるStanislas Dehaene博士も含まれている。
単語認識
読むことは複雑なプロセスであり、単語を認識し、それらの単語に意味を割り当て、対応する音に単語を関連付ける必要がある。 これらの機能は、ヒトの脳のさまざまな部分に広がっていると考えられている。
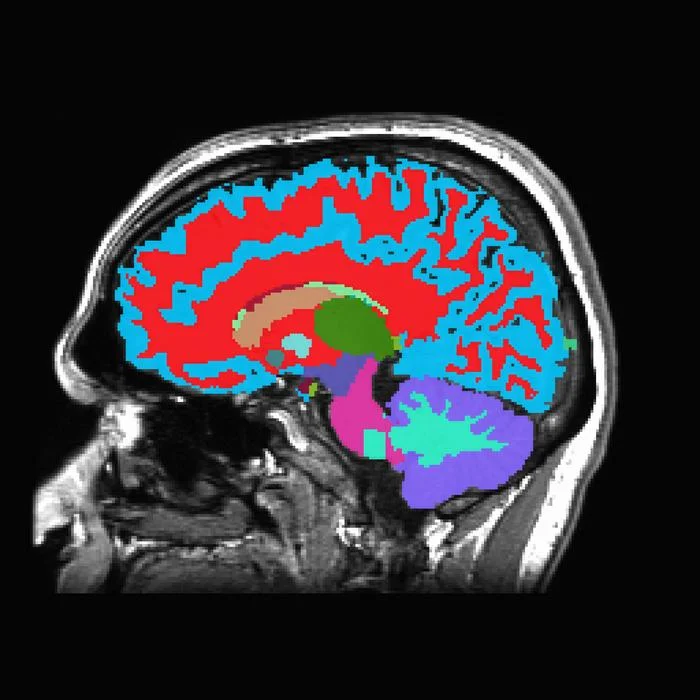
機能的磁気共鳴画像法(fMRI)の研究により、脳が書かれた単語を処理するときに点灯する視覚的単語形式領域(VWFA)と呼ばれる領域が特定された。 この領域は正字法の段階に関与している。文字の乱雑な文字列や未知のアルファベットの単語から単語を区別する。 VWFAは、視覚皮質の一部であり、オブジェクトの識別も行う下側頭葉皮質にある。
2012年にScience誌に発表された研究では、フランスの認知心理学者が、ヒヒが単語と非単語を区別することを学ぶことができると報告した後、DiCarlo博士とDehaene博士が単語認識の背後にある神経メカニズムの研究に興味を持つようになった。
Dehaene博士の研究室では、fMRIを使用して、オブジェクトや顔に反応する下側頭葉皮質の一部が、人が読むことを学ぶと、書かれた単語を認識するのに非常に特化することを以前に発見している。
「しかし、ヒトのイメージング手法の制限を考えると、これらの表現を個々のニューロンの解像度で特徴付け、これらの表現が正射投影処理をサポートするために再利用できるかどうか、またどのように再利用できるかを定量的にテストすることは困難だった」とDehaene博士は述べている。 「これらの発見は、ヒト以外の霊長類が正投影処理の根底にあるニューロンのメカニズムを調査するユニークな機会を提供できるかどうかを尋ねるきっかけになった。」
研究者らは、霊長類の脳の一部がテキストを処理する素因がある場合、彼らは単語を見るだけで非ヒト霊長類の神経活動にそのパターンを見つけることができるかもしれないと仮定した。
そのアイデアをテストするために、研究者らはマカクの下側頭葉皮質全体の約500の神経部位からの神経活動を記録した。その中には、2,000の文字列があり、その一部は英語の単語であり、一部は無意味な文字列だった。
「この方法論の効率は、何かをするために動物を訓練する必要がないことだ」とRajalingham博士は言う。 「することは、動物の前で画像をフラッシュするときの神経活動のパターンを記録することだけだ。」
その後、研究者はその神経データを線形分類子と呼ばれる単純なコンピューターモデルに送った。 このモデルは、500の神経部位のそれぞれからの入力を組み合わせて、その活動パターンを引き起こした文字列が単語であるかどうかを予測することを学習する。 動物自体はこのタスクを実行していないが、モデルは神経データを使用して行動を生成する「代替手段」として機能すると、Rajalingham博士は述べた。
そのニューラルデータを使用して、このモデルは、単語と非単語を区別したり、特定の文字が単語の文字列に存在するかどうかを判断したりするなど、多くの正射投影タスクの正確な予測を生成できた。 このモデルは、単語と非単語を区別する際に約70%の正確さだった。これは、2012年のヒヒに関する科学研究で報告された率と非常によく似ている。 さらに、このモデルによって作成されたエラーのパターンは、動物によって作成されたものと同様だった。
神経循環
研究者らはまた、視覚皮質の一部であるV4である下側頭葉皮質にも供給される、異なる脳領域からの神経活動を記録した。 彼らがV4活動パターンを線形分類子モデルに供給した場合、モデルは正射投影処理タスクでのヒトまたはヒヒのパフォーマンスを(下側頭葉皮質と比較して)十分に予測できなかった。
この調査結果は、下側頭葉皮質が読書に必要なスキルに転用されるのに特に適していることを示唆しており、読書のメカニズムの一部はオブジェクト認識の高度に進化したメカニズムに基づいているという仮説を支持していると述べている。
この研究者らは今、正射投影のタスクを実行するために動物を訓練し、彼らがタスクを学ぶにつれて彼らの神経活動がどのように変化するかを測定することを計画している。
BioQuick News:Key Brain Region Was “Recycled” As Humans Developed Ability to Read; Part of Visual Cortex Dedicated to Recognizing Objects Appears Predisposed to Identifying Words & Letters, MIT Study Finds